Интернет находится на переломном этапе. Продолжающийся рост блокирования рекламы положил конец модели доходов, которая опирается исключительно на рекламные доллары для управления веб-сайтами и предприятиями.
В частности, новостные сайты начали экспериментировать со способами диверсификации источников дохода, и одним из наиболее заметных вариантов, которые все сайты, такие как The Wall Street Journal, Financial Times, The New York Times или The Washington Post, были реализованы, является система платного доступа.
Существуют различные типы платных сетей, но их объединяет то, что они блокируют доступ к контенту либо напрямую, либо после прочтения определенного количества статей на сайте.
Затем посетителей просят подписаться на сайт, чтобы продолжить чтение статей на нем.
Это может иметь смысл с точки зрения бизнеса и может быть более прибыльным, чем бороться с пользователями, которые запускают блокировщики рекламы, но есть и обратная сторона как для платного сайта, так и для заблокированного пользователя.
Сайты теряют высокий процент посетителей, если внедряют систему платного доступа. Неясно, насколько велик этот процент на самом деле, и, вероятно, он варьируется от сайта к сайту, но, вероятно, он намного выше, чем процент посетителей, которые подписываются на сайт после того, как им предоставляется возможность подписаться на чтение желаемой статьи.
Маскарад вашего браузера
Не секрет, что новостные сайты предоставляют доступ к новостным агрегаторам и поисковым системам. Если вы посмотрите, например, Новости Google или Поиск, вы найдете статьи с сайтов с платными сетями, перечисленными там.
В прошлом новостные сайты давали доступ посетителям, приходящим из крупных новостных агрегаторов, таких как Reddit, Digg или Slashdot, но в настоящее время эта практика кажется такой же хорошей, как и мертвая.
Другой прием - вставить заголовок статьи в поисковую систему для непосредственного чтения кешированной истории, похоже, больше не работает должным образом, так как статьи на сайтах с платными сетями обычно больше не кэшируются.
Обновление : The Wall Street Journal объявил, что закроет дыру, описанную ниже. Вы все еще можете читать статьи за платным доступом к сайту, однако, используя следующий метод:
- Нажмите F12, когда вы находитесь на странице статьи с обрезанной статьей, и запросите подписку, чтобы прочитать ее полностью.
- Откройте вкладку консоли.
- Вставьте javascript: window.location = "// m.facebook.com/l.php?u="+encodeURIComponent(window.location.href);
- Нажмите Enter.
Страница должна перезагрузиться, а статья должна быть загружена полностью. Вы также можете разместить ссылку на статью в Facebook, например, в новом сообщении, которое могут видеть только вы. Нажав на опубликованную ссылку, вы должны загрузить статью целиком на веб-сайте The Wall Street Journal.
Пользователь-агент и реферер
Вам, наверное, интересно, как сайты блокируют или разрешают доступ к контенту сайта. Методы с годами улучшились, и уже недостаточно просто изменить реферер браузера на //www.google.com/, чтобы получить полный доступ к контенту сайта.
Вместо этого сайты используют различные проверки, которые включают в себя пользовательский агент, реферер и куки, а иногда даже больше, чтобы определить законность доступа.
Основная информация
Вероятно, лучший способ замаскировать браузер - сделать его роботом Google.
- Реферер: //www.google.com/
- Пользователь-агент: Mozilla / 5.0 (совместимо; Googlebot / 2.1; + // www.google.com/bot.html
Fire Fox
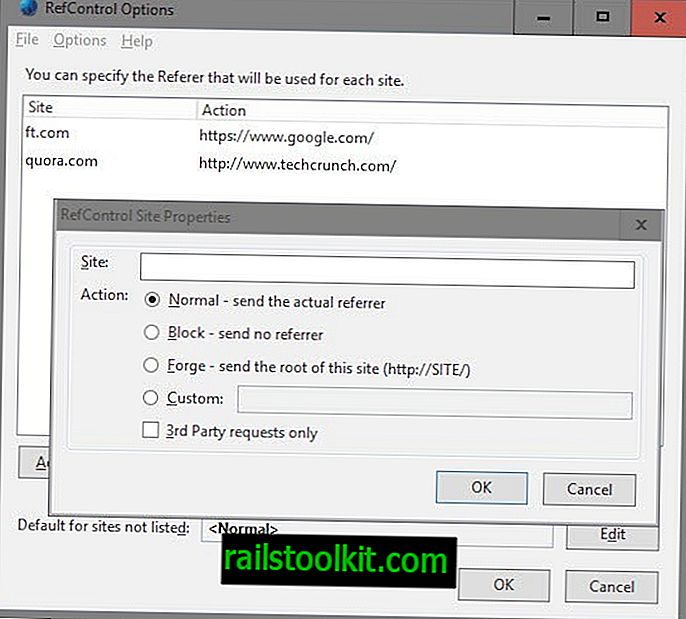
Для этого пользователям Firefox нужны две надстройки браузера: первая, RefControl, для изменения значения реферера при посещении новостных сайтов, вторая, User Agent Switcher, для смены пользовательского агента браузера.
- Загрузите и установите оба расширения в веб-браузере Firefox.
- Нажмите на клавишу Alt и выберите Инструменты> Параметры RefControl.
- Нажмите «Добавить сайт», введите доменное имя под сайтом, выберите настраиваемое действие и введите //www.google.com/ в качестве реферала.
- Повторите это для всех новостных сайтов, к которым вы хотите получить доступ (некоторые могут не работать, даже если вы вносите изменения, так что имейте это в виду).
- Когда вы закончите, закройте окно конфигурации.
- Снова нажмите Alt-клавишу и в меню выберите «Инструменты»> «Пользовательский агент по умолчанию»> «Изменить пользовательские агенты».
- Выберите «Создать»> «Агент пользователя» и замените строку в поле «Агент пользователя» на Mozilla / 5.0 (совместимо; Googlebot / 2.1; + // www.google.com/bot.html). Назовите это Googlebot.
- Выйти из меню.
- Прежде чем получить доступ к этим сайтам, нажмите Alt и выберите Пользовательский агент по умолчанию> Googlebot.
Это все, что нужно сделать. Немного прискорбно, что в Firefox нет расширения, которое автоматически изменяет пользовательский агент в зависимости от посещаемых вами сайтов.
Гугл Хром
Пользователи Google Chrome могут установить расширения, такие как User Agent Switcher и Referer Control, которые доступны для браузера, чтобы сделать то же самое.
Однако есть и другая возможность - создать собственное расширение, которое автоматизирует процесс в браузере.
Инструкции предоставляются на Elaineou. Все, что требуется, в основном, это создать новый каталог на локальном компьютере, создать в нем два файла background.js и manifest.json, а также скопировать и вставить код, найденный на сайте, в файлы.
Вам нужно включить «режим разработчика» в chrome: // extensions /, а затем выбрать «загрузить распакованное расширение», чтобы выбрать папку, в которой вы создали два файла, для загрузки расширения в Chrome.
Вы можете изменить список сайтов, которые он поддерживает, чтобы добавить новые.